Strategy. Innovation. Brand.
Spotting Random Fraud
Let’s say we have an election and 20 precincts report their results. Here’s the total number of votes cast in each precinct:
3271 2987 2769 3389
2587 3266 4022 4231
3779 3378 4388 5327
2964 2864 2676 3653
3453 4156 3668 4218
Why would you suspect fraud?
Before you answer that, let me ask you another question. Would you please write down a random number between one and 20?
Asking you to write down a random number seems like an innocent request. But the word “random” invokes some unusual behavior. It turns out that we all have in our minds a definition of “random” that’s not quite … well, random. Does the number 17 seem random to you? Most people would say, “Sure. That’s pretty random.” Do the numbers 10 and 15 seem random to you? Most people would say, “No. Those aren’t random numbers.”
Why do we have a bias against 10 and 15? Why do we say they aren’t random? Probably because we often round our numbers so that they end in zeros or fives. We say, “I’ll see you in five minutes (or 10 minutes or 15 minutes)”. We rarely say, “I’ll see you in 17 minutes”. In casual conversation, we use numbers that end in zeros or fives far more often than we use numbers that end in other digits. Because we use them frequently, they seem familiar, not random.
So, if we want numbers to look random – as we might in a fraud – we’ll create numbers that fit our assumptions of what random numbers look like. We’ll under-represent numbers that end in fives and zeros and over-represent numbers that end in sevens or threes or nines. But if the numbers are truly random, then all the digits zero through nine should be equally represented.
Now look again at the reported numbers from the precincts. What’s odd is what’s missing. None of the twenty numbers end in five or zero. But if the numbers were truly random, we would expect – in a list of 20 — at least two numbers to end in zero and two more to end in five. The precinct numbers are suspicious. Somebody was trying to make the numbers look random but tripped over their own assumptions about what random numbers look like.
Moral of the story? If you’re going to cheat, check your assumptions at the door.
By the way, I ask my students to write down a random number between one and 20. The most frequent number is 17, followed by 3, 13, 7, and 9. There is a strong bias towards odd numbers and whole numbers. No one has ever written down a number with a fraction.
Knowledge Neglect — Scots In Saris

Sari!
If I ask you about the crime rate in your neighborhood, you probably won’t have a clear and precise answer. Instead, you’ll make a guess. What’s the guess based on? Mainly on your memory:
- If you can easily remember a violent crime, you’ll guess that the crime rate is high.
- If you can’t easily remember such a crime, you’ll guess a much lower rate.
Our estimates, then, are not based on reality but on memory, which of course is often faulty. This is the availability bias. Our probability estimates are biased toward what is readily available to memory.
The broader concept is processing fluency– the ease with which information is processed. In general, people are more likely to judge a statement to be true if it’s easy to process. This is the illusory truth effect– we judge truth based on ease-of-processing rather than objective reality.
It follows that we can manipulate judgment by manipulating processing fluency. Highly fluent information (low cognitive cost) is more likely to be judged true.
We can manipulate processing fluency simply by changing fonts. Information presented in easy-to-read fonts is more likely to be judged true than is information presented in more challenging fonts. (We might surmise that the new Sans Forgetica font has an important effect on processing fluency).
We can also manipulate processing fluency by repeating information. If we’ve seen or heard the information before, it’s easier to process and more likely to be judged true. This is especially the case when we have no prior knowledge about the information.
But what if we do have prior knowledge? Will we search our memory banks to find it? Or will we evaluate truthfulness based on processing fluency? Does knowledge trump fluency or does fluency trump knowledge?
Knowledge-trumps-fluency is known as the Knowledge-Conditional Model. The opposite is the Fluency-Conditional Model. Until recently, many researchers assumed that people would default to the Knowledge-Conditional Model. If we knew something about the information presented, we would retrieve that knowledge and use it to judge the information’s truthfulness. We wouldn’t judge truthfulness based on fluency unless we had no prior knowledge about the information.
A 2015 study by Lisa Fazio et. al. starts to flip this assumption on its head. The article’s title summarizes the finding: “Knowledge Does Not Protect Against Illusory Truth”. The authors write that, “An abundance of empirical work demonstrates that fluency affects judgments of new information, but how does fluency influence the evaluation of information already stored in memory?”
The findings – based on two experiments with 40 students from Duke University – suggest that fluency trumps knowledge. Quoting from the study:
“Reading a statement like ‘A sari is the name of the short pleated skirt worn by Scots’ increased participants later belief that it was true, even if they could correctly answer the question, ‘What is the name of the short pleated skirt worn by Scots?’” (Emphasis added).
The researchers found similar examples of knowledge neglect– “the failure to appropriately apply stored knowledge” — throughout the study. In other words, just because we know something doesn’t mean that we use our knowledge effectively.
Note that knowledge neglect is similar to the many other cognitive biases that influence our judgment. It’s easy (“cognitively inexpensive”) and often leads us to the correct answer. Just like other biases, however, it can also lead us astray. When it does, we are predictably irrational.
Concept Creep and Pessimism

What’s your definition of blue?
My friend, Andy, once taught in the Semester at Sea program. The program has an ocean-going ship and brings undergraduates together for a semester of sea travel, classes, and port calls. Andy told me that he was fascinated watching these youngsters come together and form in-groups and out-groups. The cliques were fairly stable while the ship was at sea but more fluid when it was in port.
Andy told me, for instance, that some of the women described some of the men as “Ship cute, shore ugly.” The very concept of “cute” was flexible and depended entirely on context. When at sea, a limited supply of men caused the “cute” definition to expand. In port, with more men available, the definition of cute became more stringent.
We usually think of concepts as more-or-less fixed. They’re unlike other processes that expand over time. The military, for instance is familiar with “mission creep” – a mission may start with small and well-defined objectives but they often grow over time. Similarly, software developers understand “feature creep” – new features are added as the software is developed. But do concepts creep? The Semester at Sea example suggests that they do, depending on prevalence.
This was also the finding of a research paper published in a recent issue of Science magazine. (Click here). Led by David Levari, the researchers showed that “… people often respond to decreases in the prevalence of a stimulus by expanding their concept of it.” In the Semester at Sea example, as the stimulus (men) decreases, the concept of cute expands. According to Levari, et. al., this is a common phenomenon and not just related to hormonal youngsters isolated on a ship.
The researchers started with a very neutral stimulus – the color of dots. They presented 1,000 dots ranging in color from purple to blue and asked participants to identify the blue ones. They repeated the trial several hundred times. Participants were remarkably consistent in each trial. Dots identified as blue in the first trials were still identified as blue in the last trials.
The researchers then repeated the trials while reducing the number of blue dots. Would participants in the second set of trials – with decreased stimulus — expand their definition of “blue” and identify dots as blue that they had originally identified as purple? Indeed, they would. In fact, the number of purple-to-blue “crossover” dots was remarkably consistent through numerous trials.
The researchers also varied the instructions for the comparisons. In the first study, participants were told that the number of blue dots “might change” in the second pass. In a second study, participants were told that the number of blue dots would “definitely decrease.” In a third study, participants were instructed to “be consistent” and were offered monetary rewards for doing so. In some studies the number of blue dots declined gradually. In others, the blue dots decreased abruptly. These procedural changes had virtually no impact on the results. In all cases, declining numbers of blue dots resulted in an expanded definition of “blue”.
Does concept creep extend beyond dots? The researchers did similar trials with 800 images of human faces that had been rated on a continuum from “very threatening” to “not very threatening.” The results were essentially the same as the dot studies. When the researchers reduced the number of threatening faces, participants expanded their definition of “threatening.”
All these tests used visual stimuli. Does concept creep also apply to nonvisual stimuli? To test this, the researchers asked participants to evaluate whether 240 research proposals were ethical or not. The results were essentially the same. When the participants saw many unethical proposals, their definition of ethics was fairly stringent. When they saw fewer unethical proposals, their definition expanded.
It seems then that “prevalence-induced concept change” – as the researchers label it – is probably common in human behavior. Could this help explain some of the pessimism in today’s world? For example, numerous sources verify that the crime rate in the United States has declined over the past two decade. (See here, here, and here, for example). Yet many people believe that the crime rate has soared. Could concept creep be part of the problem? It certainly seems likely.
Yet again, our perception of reality differs from actual reality. Like other cognitive biases, concept creep distorts our perception in predictable ways. As the number of stimuli – from cute to blue to ethical – goes down, we expand our definition of what the concept actually means. As “bad news” decreases, we expand our definition of what is “bad”. No wonder we’re pessimistic.
How Many Cognitive Biases Are There?
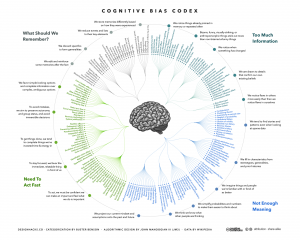
Source: Wikipedia — List_of_cognitive_biases
In my critical thinking class, we begin by studying 17 cognitive biases that are drawn from Peter Facione’s excellent textbook, Think Critically. (I’ve also summarized these here, here, here, and here). I like the way Facione organizes and describes the major biases. His work is very teachable. And 17 is a manageable number of biases to teach and discuss.
While the 17 biases provide a good introduction to the topic, there are more biases that we need to be aware of. For instance, there’s the survivorship bias. Then there’s swimmer’s body fallacy. And the Ikea effect. And the self-herding bias. And don’t forget the fallacy fallacy. How many biases are there in total? Well, it depends on who’s counting and how many hairs we’d like to split. One author says there are 25. Another suggests that there are 53. Whatever the precise number, there are enough cognitive biases that leading consulting firms like McKinsey now have “debiasing” practices to help their clients make better decisions.
The ultimate list of cognitive biases probably comes from Wikipedia, which identifies 104 biases. (Click here and here). Frankly, I think Wikipedia is splitting hairs. But I do like the way Wikipedia organizes the various biases into four major categories. The categorization helps us think about how biases arise and, therefore, how we might overcome them. The four categories are:
1) Biases that arise from too much information – examples include: We notice things already primed in memory. We notice (and remember) vivid or bizarre events. We notice (and attend to) details that confirm our beliefs.
2) Not enough meaning – examples include: We fill in blanks from stereotypes and prior experience. We conclude that things that we’re familiar with are better in some regard than things we’re not familiar with. We calculate risk based on what we remember (and we remember vivid or bizarre events).
3) How we remember – examples include: We reduce events (and memories of events) to the key elements. We edit memories after the fact. We conflate memories that happened at similar times even though in different places or that happened in the same place even though at different times, … or with the same people, etc.
4) The need to act fast – examples include: We favor simple options with more complete information over more complex options with less complete information. Inertia – if we’ve started something, we continue to pursue it rather than changing to a different option.
It’s hard to keep 17 things in mind, much less 104. But we can keep four things in mind. I find that these four categories are useful because, as I make decisions, I can ask myself simple questions, like: “Hmmm, am I suffering from too much information or not enough meaning?” I can remember these categories and carry them with me. The result is often a better decision.
Factory-Installed Biases

Born this way.
In my critical thinking class, we investigate a couple of dozen cognitive biases — fallacies in the way our brains process information and reach decisions. These include the confirmation bias, the availability bias, the survivorship bias, and many more. I call these factory-installed biases – we’re born this way.
But we haven’t asked the question behind the biases: why are we born that way? What’s the point of thinking fallaciously? From an evolutionary perspective, why haven’t these biases been bred out of us? After all, what’s the benefit of being born with, say, the confirmation bias?
Elizabeth Kolbert has just published an interesting article in The New Yorker that helps answer some of these questions. (Click here). The article reviews three new books about how we think:
- The Enigma of Reason by Hugo Mercier and Dan Sperber
- The Knowledge Illusion: Why We Never Think Alone by Steve Sloman and Philip Fernbach
- Denying To The Grave: Why We Ignore The Facts That Will Save Us by Jack Gorman and Sara Gorman
Kolbert writes that the basic idea that ties these books together is sociability as opposed to logic. Our brains didn’t evolve to be logical. They evolved to help us be more sociable. Here’s how Kolbert explains it:
“Humans’ biggest advantage over other species is our ability to coöperate. Coöperation is difficult to establish and almost as difficult to sustain. For any individual, freeloading is always the best course of action. Reason developed not to enable us to solve abstract, logical problems or even to help us draw conclusions from unfamiliar data; rather, it developed to resolve the problems posed by living in collaborative groups.”
So, the confirmation bias, for instance, doesn’t help us make good, logical decisions but it does help us cooperate with others. If you say something that confirms what I already believe, I’ll accept your wisdom and think more highly of you. This helps us confirm our alliance to each other and unifies our group. I know I can trust you because you see the world the same way I do.
If, on the other hand, someone in another group says something that disconfirms my belief, I know the she doesn’t agree with me. She doesn’t see the world the same way I do. I don’t see this as a logical challenge but as a social challenge. I doubt that I can work effectively with her. Rather than checking my facts, I check her off my list of trusted cooperators. An us-versus-them dynamic develops, which solidifies cooperation in my group.
Mercier and Sperber, in fact, change the name of the confirmation bias to the “myside bias”. I cooperate with my side. I don’t cooperate with people who don’t confirm my side.
Why wouldn’t the confirmation/myside bias have gone away? Kolbert quotes Mercier and Sperber: ““This is one of many cases in which the environment changed too quickly for natural selection to catch up.” All we have to do is wait 1,000 generations or so. Or maybe we can program artificial intelligence to solve the problem.
My Social Media
![]()
![]()
![]()
![]()
